
1. 事务
满足ACID的一组操作, 使用Commit和Rollback操作
MySQLd 每个查询都是AUTOCOMMIT
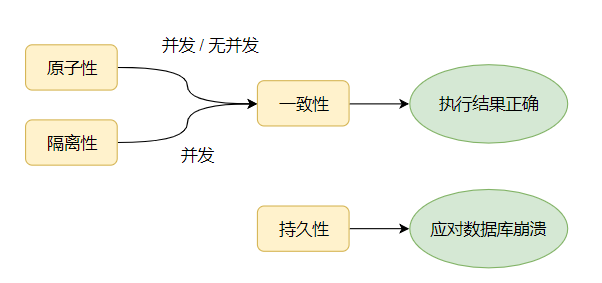
- Atomicity(原子性): 全部成功,要么全部失败
- Consistency(一致性): AB两账户无论转账, 总额不会改变
- Isolation(隔离性): 多个用户并发访问数据库时, 多个并发事务之间相互隔离
- Durability(持久性): 一旦事务提交,则其所做的修改将会永远保存到数据库中
二. 范式
一般满足3NF足够
- 1NF: 属性不可分
- 2NF: 属性完全依赖于主键(消除部分子函数依赖)
- 3NF: 属性不依赖于其他非主属性(消除传递依赖)
- BCNF: 任何非主属性不能对主键子集依赖[消除对主码子集的依赖]
三. 锁🔒
1. 共享锁与排他锁
- 共享锁: 多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
- 排他锁: 不能与其他所并存, 但是获取排他锁的事务是可以对数据就行读取和修改。
- update,delete,insert都会自动加上排他锁
- select语句默认不会加任何锁, 并且直接select不存在锁限制
- select
- 加共享锁:
select ... lock in share mode - 加排他锁:
select ...for update
- 加共享锁:
2. 悲观锁与乐观锁
悲观锁和乐观锁都是业务逻辑层次的定义,不同的设计可能会有不同的实现。
-
在mysql层常用的悲观锁实现方式是加一个排他锁。
begin; select * from account where id = 1 for update; update account set balance=150 where id =1; commit; -
乐观锁是指在获取数据时候不加锁,乐观的认为操作不会有冲突,在update的时候再去检查冲突。
begin; select balance from account where id=1; -- 得到balance=100;然后计算balance=100+50=150 update account set balance = 150 where id=1 and balance = 100; commit;
四. 并发一致性
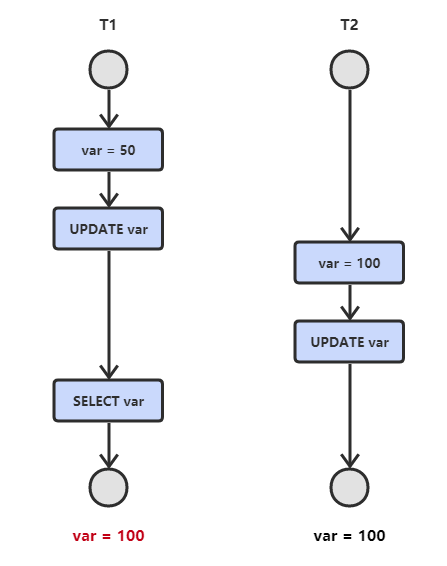
1. 丢失修改
解决办法: 事务+查询共享锁
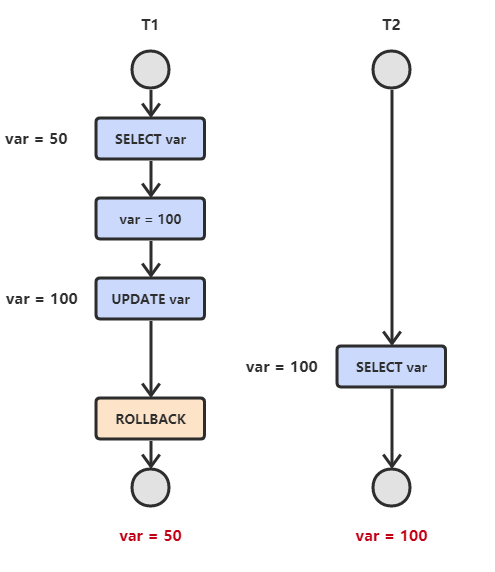
2. 脏读
解决办法:
- 把数据库的事务隔离级别调整到 READ_COMMITTED
- 共享锁select
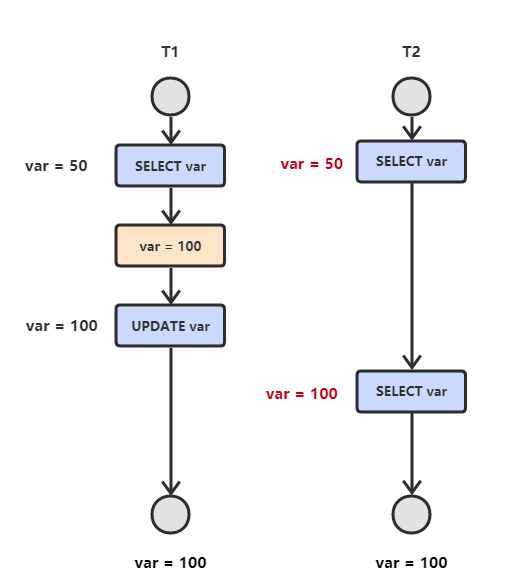
3. 不可重复读
解决办法:
- 数据库的事务隔离级别调整到REPEATABLE_READ
- select共享锁
4. 幻读
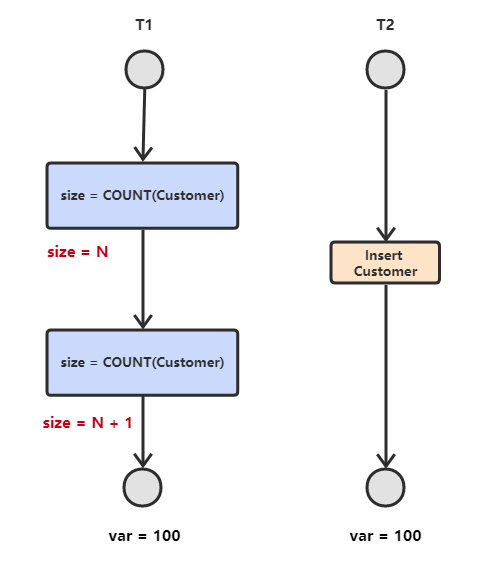
五. 数据类型
1. 整形
| Tinyint | smallint | mediumint | int | bigint | |
|---|---|---|---|---|---|
| bit | 1*8 | 2*8 | 3*8 | 4*8 | 8*8 |
2. 浮点型
FLOAT, DOUBLE(浮点类型) DECIMAL(高精度小数类型, CPU不原生支持)
3. 字符串
CHAR, VARCHAR
4. 时间和日期
- DATETIME(8字节)“2008-01-16 22:37:08”
- TIMESTAMP(4字节), 与时区有关
六. 索引
- 对于非常小的表、大部分情况下简单的全表扫描比建立索引更高效。
- 对于中到大型的表,索引就非常有效。
- 但是对于特大型的表,建立和维护索引的代价将会随之增长。 需要用到一种技术可以直接区分出需要查询的一组数据 而不是一条记录一条记录地匹配,例如可以使用分区技术。
不同存储引擎具有不同的索引类型和实现
1. B-Tree
常用命令
-
user, host字段在mysql.user表里
select user, host from mysql.user; -
赋权
grant select on practice.* to 'chunibyo'@'%'; flush privileges -
有用户切换了他们的ip地址
RENAME USER user@ipaddress1 TO user@ipaddress2; -
查看当前使用数据库
select database();查看所有数据库
show databases; -
格式化日期
select date_format(now(), '%y-%m-%d %H:%i:%s'); -
事务
begin; XXXXX commit; / rollback; -
alter
删除teacher表name字段 alter table teacher drop name; 添加teacher表name字段 alter table teacher add name INT; alter table teacher modify name char(10); -
UNION
SELECT customerNumber FROM orders UNION ALL SELECT customerNumber FROM payments默认
distinct -
GROUP BY
根据一个或多个列对结果集进行分组。在分组的列上我们可以使用 COUNT, SUM, AVG,等函数。
-
JOIN
-
INNER JOIN
SELECT * FROM productlines INNER JOIN products on productlines.productLine = products.productLine; -
LEFT JOIN
-
RIGHT JOIN
-
-
NULL
# 正确 SELECT * FROM productlines WHERE htmlDescription IS NULL; # 错误 SELECT * FROM productlines WHERE htmlDescription = NULL;
sql 50题
-
查询” 01 “课程比” 02 “课程成绩高的学生的信息及课程分数
-
查询同时存在” 01 “课程和” 02 “课程的情况
select * from (select SId from SC where SC.CId = '01') as t1, (select SId from SC where SC.Cid = '02') as t2 where t1.SId = t2.SId;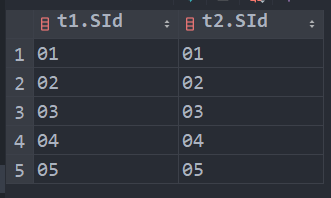
-
查询存在” 01 “课程但可能不存在” 02 “课程的情况(不存在时显示为 null )
select t1.SId, t1.CId, t2.CId from (select * from SC where CId = '01') as t1 left join (select * from SC where CId = '02') as t2 on t1.SId = t2.SId;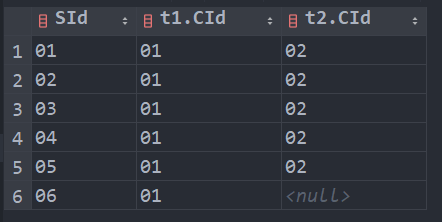
-
查询各科成绩最高分、最低分和平均分
# 14 select SC.CId, max(SC.score) as max_score, min(SC.score) as min_score, AVG(SC.score) as avg_score, count(*) as number, sum(IF(SC.score >= 60, 1, 0)) / count(*) as D, sum(IF(SC.score >= 70 and SC.score < 80, 1, 0)) / count(*) as C, sum(IF(SC.score >= 80 and SC.score < 90, 1, 0)) / count(*) as B, sum(IF(SC.score >= 90, 1, 0)) / count(*) as A from SC GROUP BY SC.CId ORDER BY count(*) DESC, SC.CId
-
各科成绩进行排序,并显示排名, Score 重复时保留名次空缺
# 15 select a.CId, a.SId, a.score, count(b.CId) + 1 as _rank from SC as a left join SC as b on a.CId = b.CId and a.score < b.score group by a.CId, a.SId, a.score order by a.CId ASC, a.score DESC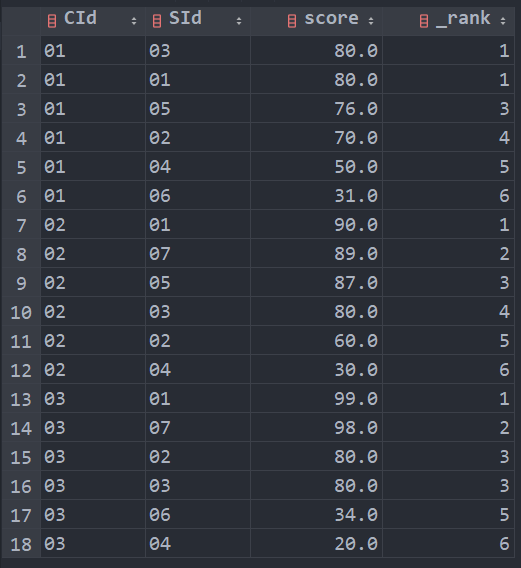
-
查询学生的总成绩,并进行排名,总分重复时不保留名次空缺